Code verification using Tijmen's mock catalogs - Strategy
User documentation
06/26/2013
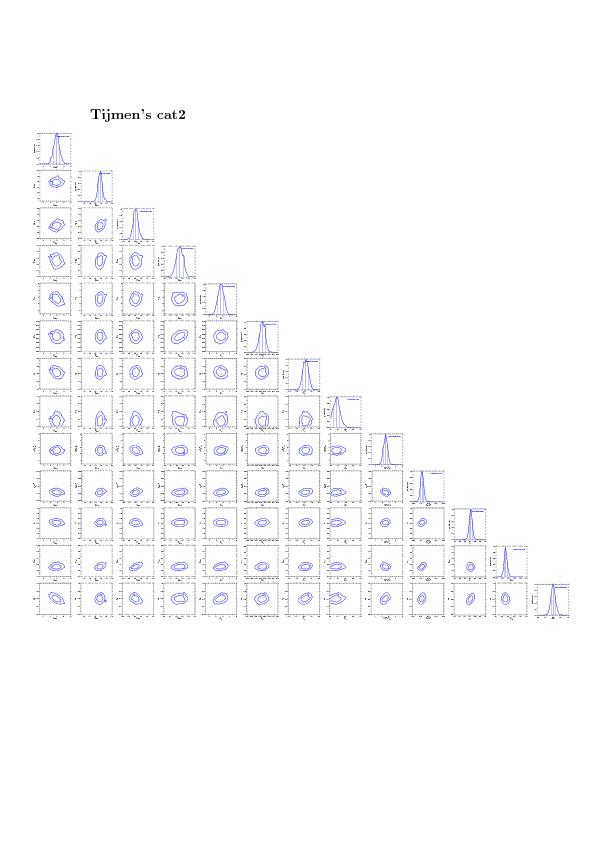
Tijmen provided 10 mock catalogs covering 2500 deg^2 containing SZ as well as X-ray Yx data.
Remember: In our approach, the number counts only use SZ data and the clusters' redshifts. The SZ scaling relation parameters are calibrated through direct comparison with Xray and/or velocity dispersion mass observables.
Input values and priors - flat LCDM¶
This table shows the input values as well as the adopted priors if applied:
A_SZ 6.0 +/- 1.8
B_SZ 1.4 +/- 0.28
C_SZ 0.6 +/- 0.3
D_SZ 0.2 +/- 0.16
A_X 5.77 +/- 0.56
B_X 0.57 +/- 0.03
C_X - 0.4 +/- 0.2
D_X 0.07 +/- 0.05
H 71.0154 +/- 2.4
Omega_m 0.262
Delta_r 2.407
sigma_8 0.797758
Analysis strategy¶
In order to confirm that every piece of the code works correctly I can split the full analysis in its different components and test e.g.- Mass calibration: Fit for SZ parameters using SZ and Xray data while keeping cosmology fixed
- Number counts: Fit for the relevant cosmological parameters (Omega_m, sigma_8, H) keeping the SZ parameters fixed (Xray is not relevant in this case)
- "Inversed number counts": Fit for the SZ parameters while keeping the cosmology fixed
- Full combined analysis: Fit for cosmology and all scaling relation parameters.
Mass calibration with fixed cosmology - no number counts¶
I analyze Tijmen's catalog0 containing 567 clusters with SZ and X-ray Yx data.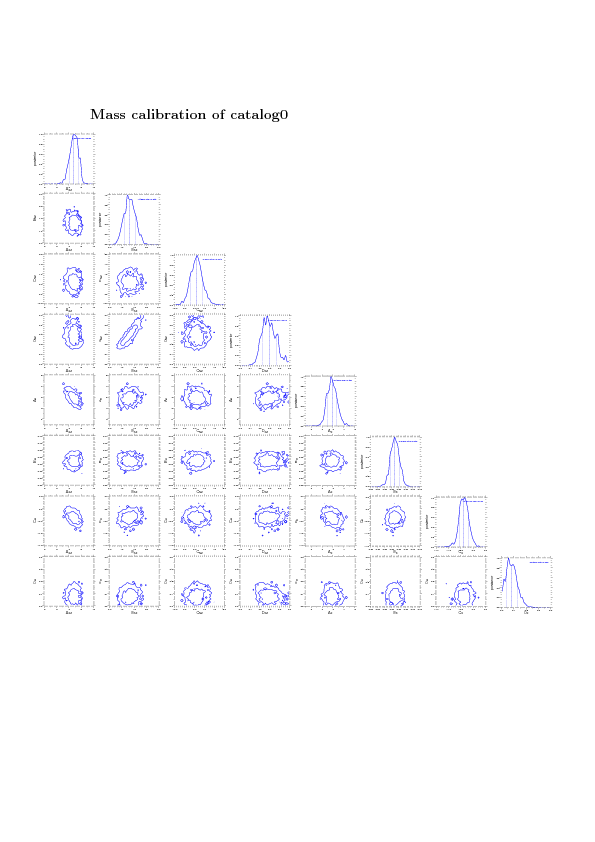
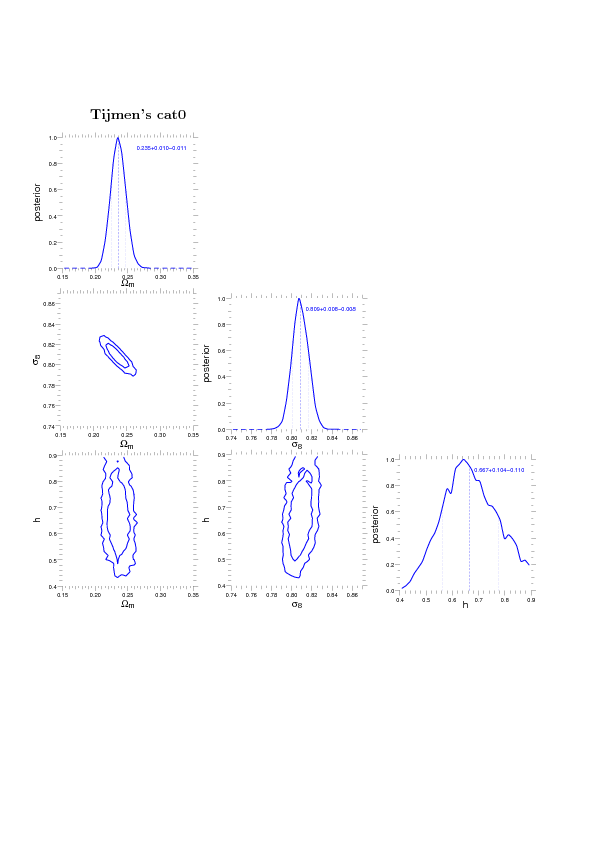
Number counts with fixed cosmology - no mass calibration¶
The base in this run is Omega_c H^2 - Delta_R.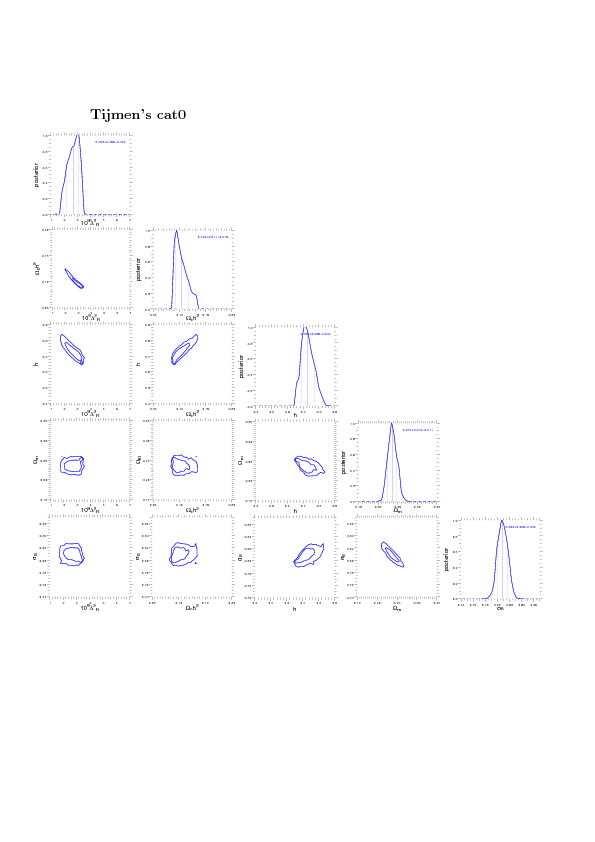
Here I use Omega_m - sigma_8. This works much better, convergence is faster and better (fully converged!)